
Daha önce kitaplığınızı aynı renk kitap kapaklarına sahip kitapları aynı raflarda veya aynı yerde olacak şekilde organize ettiniz mi? Muhtemelen ettiniz. Benzer nesneleri birlikte gruplamayı zaten biliyorsunuz. Eğer anaokulu deneyiminiz varsa bolca yapmışsınızdır. Fikir oldukça basit olsa da, bu fikirden etkilenen kullanım durumlarının miktarı inanılmazdır. Makine öğrenmesi literatüründe buna genellikle kümeleme denir –benzer nesneleri otomatik olarak aynı gruplara gruplandırır.
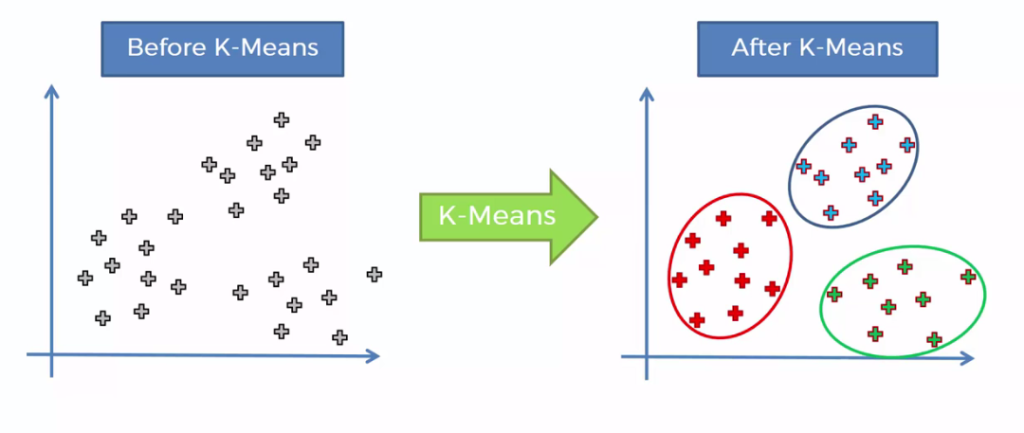
Kümeleme, verilerin yapısını anlamak için sıkça kullanılan keşifsel veri analizi tekniklerinden biridir. Bu yöntem, farklı veri noktalarının benzerliklerine ve farklılıklarına göre gruplandırılmasına dayanır. Veriler içindeki benzer özelliklere sahip veri noktalarının aynı küme içinde toplandığı bu yaklaşım, veri alt gruplarını belirleme amacı taşır.
Kümeleme, verilerin yapısını anlamak için sıkça kullanılan keşifsel veri analizi tekniklerinden biridir. Bu yöntem, farklı veri noktalarının benzerliklerine ve farklılıklarına göre gruplandırılmasına dayanır. Veriler içindeki benzer özelliklere sahip veri noktalarının aynı küme içinde toplandığı bu yaklaşım, veri alt gruplarını belirleme amacı taşır.
Bu yöntem, kümelerin birbirinden farklı olması ve küme içindeki noktaların birbirine benzer olması temeline dayanır. Yani, benzer veri noktaları aynı kümede toplanırken, farklı veri noktaları farklı kümelere ayrılır.
K-Means algoritması da bir kümeleme algoritmasıdır ve popüler, basit ve etkili bir yöntemdir. Bu algoritma, verilerin tam sayı birden başlayan bir sayıda kümelere ayrılmasına dayanır. Önceden belirlenen bir sayıda küme oluşturulur ve her bir küme, kendi merkez noktası olan bir vektör tarafından temsil edilir. K-Means algoritması, küme merkezlerinin seçilmesi, veri noktalarının en yakın küme merkezine atanması ve küme merkezlerinin güncellenmesi adımlarına dayanır. Küme merkezleri, veri noktalarından ortalama bir değer olarak belirlenir ve algoritma, küme merkezlerinin konumunu en iyi şekilde optimize etmeye çalışır. Bu optimizasyon süreci, her bir veri noktasının en yakın küme merkezine atanması ile gerçekleştirilir. K-Means algoritması, bir veri kümesi üzerinde tekrarlandığında, küme merkezlerinin yerini ve dolayısıyla kümelerin konumunu optimize eder. Bu sayede, veri noktaları en iyi şekilde gruplandırılır ve farklı kümeler arasındaki benzerlik ve farklılıklar daha belirgin hale gelir.
Bu algoritma, özellikle yüksek boyutlu veri setleri üzerinde işlem yapmak için oldukça kullanışlıdır ve kümelerin belirlenmesi ve gruplandırılması için önemli bir araçtır. K-Means algoritması, kolay uygulanabilir olması ve etkili sonuçlar vermesi nedeniyle birçok alanda kullanılmaktadır. Örneğin, pazarlama alanında, müşterilerin birbirine benzer özelliklere sahip gruplara ayrılması ve buna göre pazarlama stratejilerinin belirlenmesi için kullanılır.
Ayrıca, tıp alanında, hastalıkların teşhisinde ve tedavisinde önemli bir araçtır. Genetik verilerin analizinde ve büyük miktardaki görüntü verilerinin sınıflandırılmasında da kullanılır. Sonuç olarak, K-Means algoritması, veri kümesindeki benzerlik ve farklılıkları hızlı ve etkili bir şekilde ortaya çıkarmak için kullanılan önemli bir kümeleme yöntemidir. Bu algoritma, veri analizi ve keşfi için oldukça yararlı bir araçtır ve farklı alanlarda pek çok uygulaması bulunmaktadır.

İşte K-Means’ın kullanım alanlarına örnekler:
- Müşteri Segmentasyonu: Perakende sektöründe, müşterileri benzer davranışlara ve tercihlere sahip gruplara ayırmak için kullanılır. Bu, pazarlama stratejilerini kişiselleştirmek ve hedef kitlenin daha iyi anlaşılmasına yardımcı olur.
- Görüntü İşleme: Görüntüleri analiz etmek ve benzer özelliklere sahip nesneleri tanımak için K-Means kullanılır. Örneğin, görüntülerde renk tabanlı nesne tespiti veya sınıflandırma yapabilir.
- Doğal Dil İşleme (NLP): Metin belgelerini kategorilere ayırmak veya benzer metinleri gruplandırmak için kullanılır. Haber makaleleri, sosyal medya yorumları veya e-postalar gibi metin verileri üzerinde kullanışlıdır.
- Web Sayfası Kategorizasyonu: İnternet üzerinde milyonlarca web sayfası bulunur. K-Means, bu sayfaları benzer içerik temalarına göre gruplandırmak için kullanılabilir.
- Sağlık Hizmetleri: Hastane kayıtları, hasta verileri ve tedavi sonuçlarını analiz etmek için kullanılabilir. Benzer hastaları tanımlayarak tedavi yaklaşımlarını kişiselleştirmeye yardımcı olur.
- E-ticaret Öneri Sistemleri: Alışveriş siteleri, müşterilere benzer ürünleri önermek için K-Means’ı kullanabilir. Bu, müşteri deneyimini iyileştirmeye yardımcı olur.
- Finansal Analiz: Finansal verileri incelemek ve benzer yatırım fırsatlarını gruplandırmak için kullanılır. Portföy yönetimi, hisse senetleri analizi ve risk yönetimi gibi alanlarda kullanımı vardır.
- Coğrafi Bilgi Sistemleri (GIS): Harita verilerini analiz etmek için kullanılabilir. Örneğin, benzer iklim bölgelerini veya benzer doğal afet risklerini tanımlamak için kullanılabilir.
- Biyomedikal Araştırma: Genetik verilerin analizi ve hastalık sınıflandırması gibi biyomedikal uygulamalarda kullanılır.
- Kalite Kontrol: Üretim süreçlerinde hataları veya kalite sorunlarını tespit etmek ve düzeltmek için kullanılabilir.
- Suç Yerlerinin Belirlenmesi: Bir şehirdeki belirli bölgelerde mevcut olan suçlarla ilgili veriler, suç kategorisi, suç alanı ve ikisi arasındaki ilişki, bir şehirdeki ya da bölgedeki suça eğilimli alanlara ilişkin bilgiler verebilir. Bununla ilgili bir makale..
Bu örnekler, K-Means’ın çok yönlü bir kümeleme algoritması olduğunu göstermektedir. Herhangi bir veri setini benzer özelliklere göre gruplandırmak ve içgörüler elde etmek için kullanılabilir.
K-Means algoritması, veri analizi, keşfi ve sınıflandırma konularında oldukça geniş bir uygulama yelpazesi sunan güçlü bir araçtır. Bu algoritma, benzerlik ve farklılıkları ortaya çıkarmak için verileri otomatik olarak gruplandırarak değerli içgörüler elde etmemizi sağlar. Özellikle müşteri segmentasyonundan finansal analize, sağlık hizmetlerinden suç analizine kadar birçok alanda kullanılabilir.
K-Means, bir kitaplığı düzenlerken benzer renklere sahip kitapları aynı rafta tutmamızı hatırlatan basit bir kavramdan türetilmiş bir algoritma olmasına rağmen, karmaşık veri setleri üzerinde büyük etkileri olan bir yaklaşım sunar. Verileri daha iyi anlamak ve daha iyi kararlar almak için güçlü bir araç olan K-Means, veri bilimcileri ve analistler için vazgeçilmez bir yardımcıdır.
Sonuç olarak, K-Means algoritması veri dünyasının karmaşıklığını basit ve anlaşılır bir şekilde ele alır, verileri gruplandırır ve içgörüler sunar. Bu sayede iş dünyasında, araştırmalarda ve birçok farklı alanda daha iyi kararlar almak için önemli bir rol oynar.
Ömer Doğan


4 yorum
Quality articles or reviews is the key to interest the users to go to see the web site,
that’s what this web page is providing.
I used to be able to find good advice from your articles.
Thanks , I’ve recently been looking for information approximately
this subject for ages and yours is the best I have found out till now.
But, what concerning the bottom line? Are you
certain concerning the supply?
Hello very cool website!! Man .. Excellent .. Superb ..
I’ll bookmark your blog and take the feeds also? I am happy to find numerous helpful information right here in the put up, we’d like work out more strategies on this regard, thanks for
sharing. . . . . .